
𝐔𝐧𝐝𝐞𝐫𝐬𝐭𝐚𝐧𝐝𝐢𝐧𝐠 𝐑𝐀𝐆 𝐟𝐫𝐨𝐦 𝐒𝐜𝐫𝐚𝐭𝐜𝐡

Let’s understand how RAG works from scratch.
RAG stands for Retrieval Augmented Generation. RAG helps to reduce hallucinations in LLMs by providing them with relevant contexts from external knowledge sources.
Understanding how RAG works from scratch is important for AI/ML Engineers.
𝐇𝐨𝐰 𝐝𝐨𝐞𝐬 𝐑𝐀𝐆 𝐰𝐨𝐫𝐤?
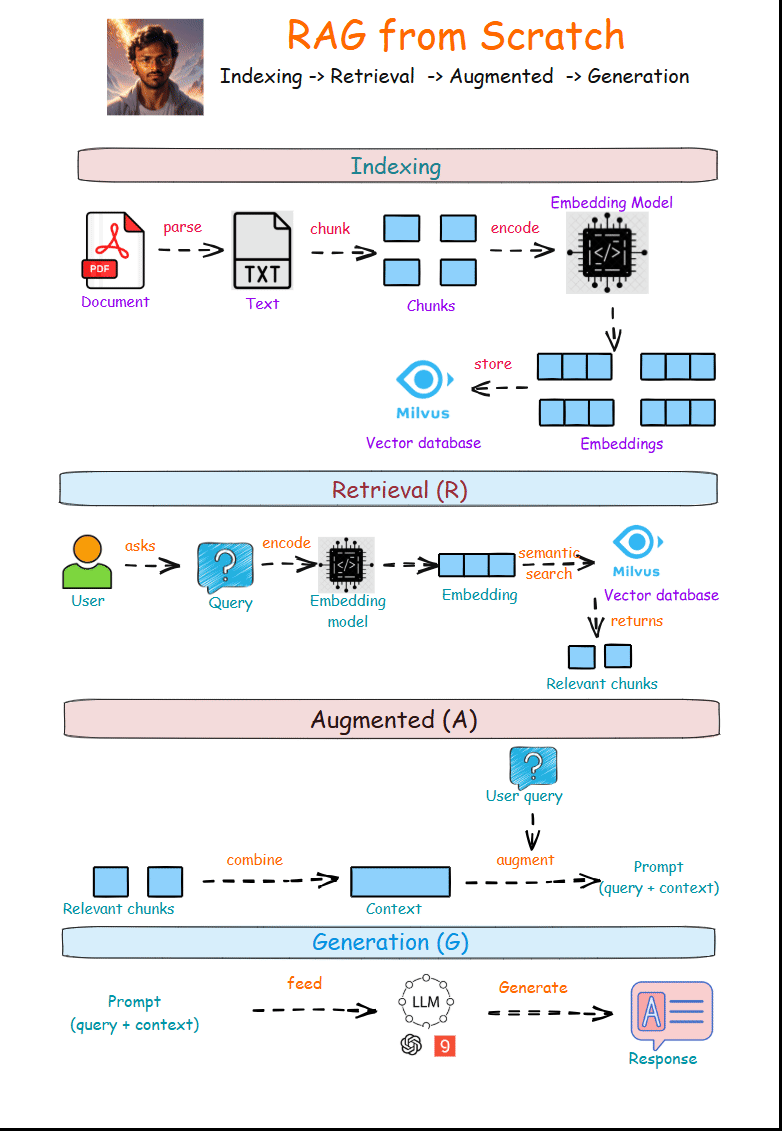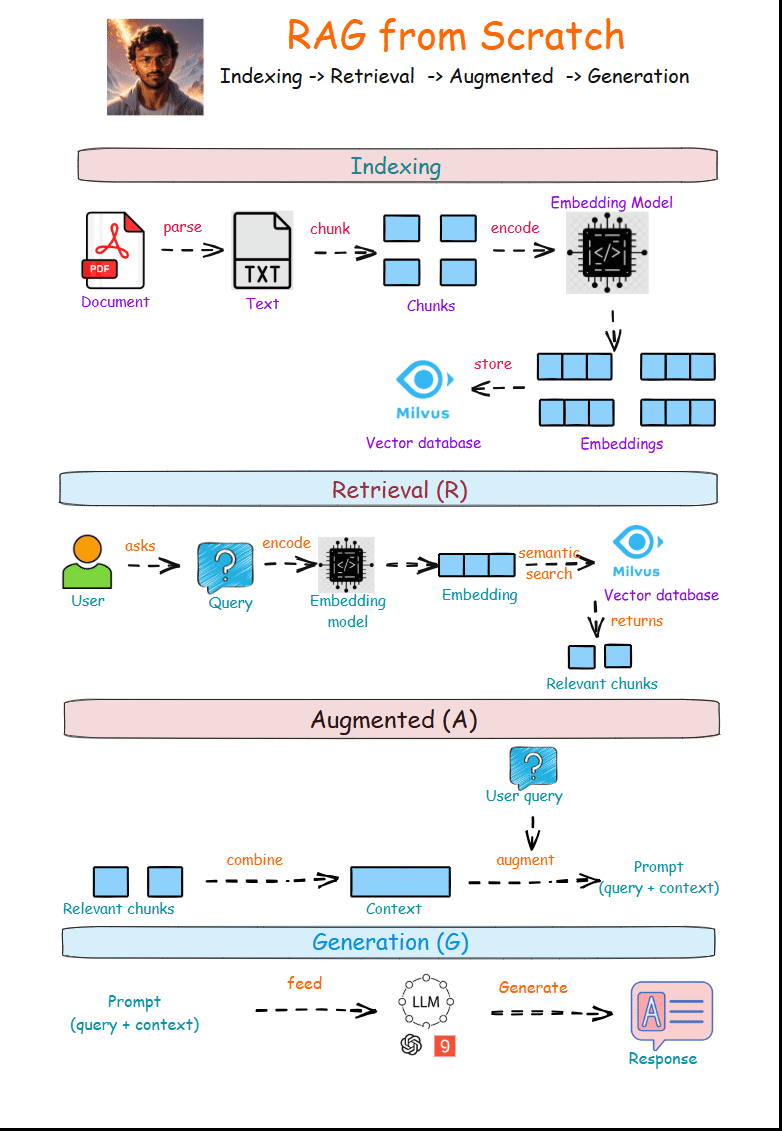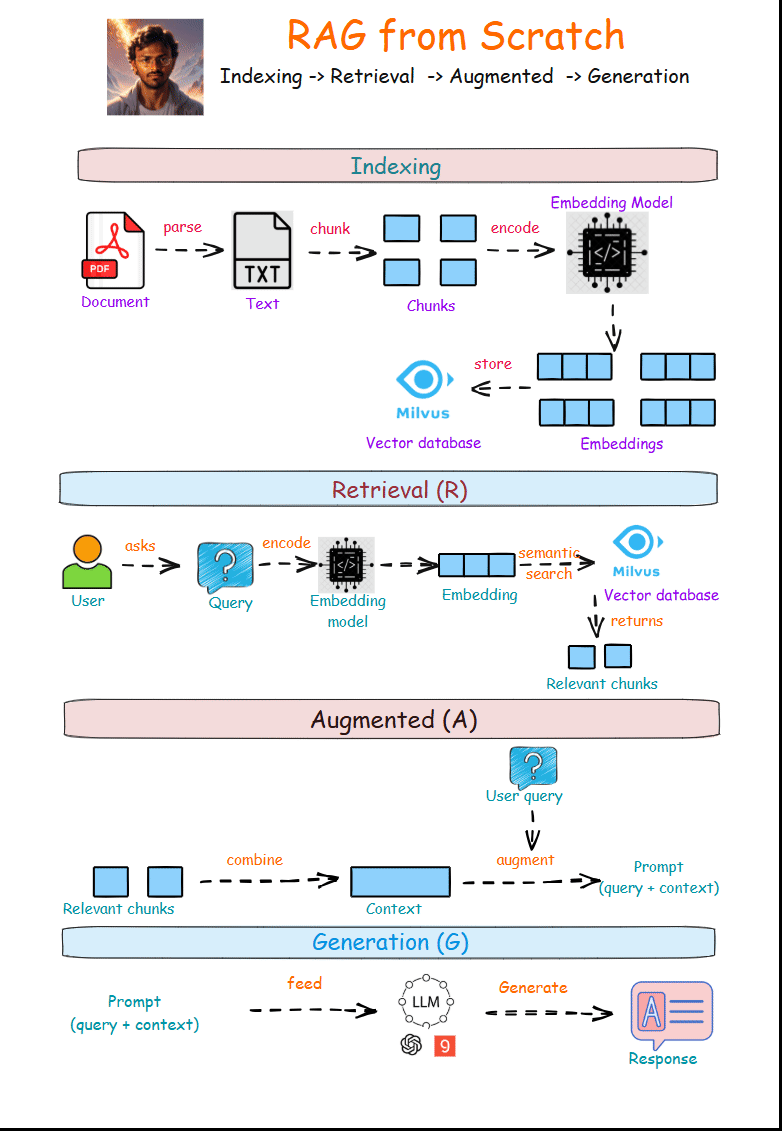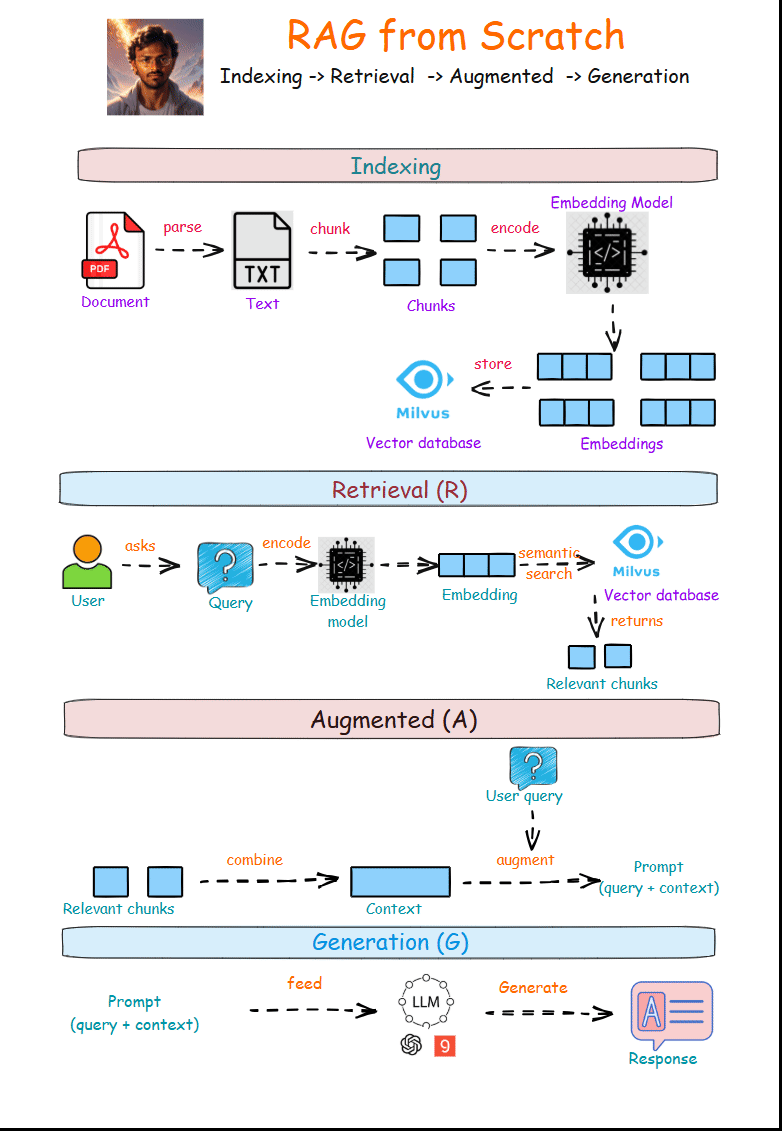
RAG involves four steps, namely indexing, retrieval, augmentation, and generation. The indexing step is done only once, while the retrieval, augmentation, and generation steps are repeated for each user query.
𝐈𝐧𝐝𝐞𝐱𝐢𝐧𝐠
This step starts with extracting the content of raw documents (parsing) and then breaking them up into smaller pieces called chunks.
An embedding model turns these chunks into vector embeddings, which are then stored in a vector database.
1️⃣ Parse: Extract content from the documents (web pages, PDFs, etc.).
2️⃣ Chunking: Split the extracted content into smaller and meaningful segments called chunks.
3️⃣ Encode: The embedding model converts chunks into embeddings.
4️⃣ Store: For quick and efficient similarity search, save chunk embeddings in a vector database.
RAG from Scratch (Webinar)
In this webinar, you will understand and implement RAG from scratch without using any frameworks like LangChain or Llama Index.
This webinar covers
What is RAG?
How does RAG address LLM limitations?
How does RAG work? ( Indexing -> Retrieval -> Augmentation -> Generation)
RAG implementation from scratch without any frameworks
Practical RAG Applications
RAG Limitations
➡️ Register

𝐑𝐞𝐭𝐫𝐢𝐞𝐯𝐚𝐥
This step starts with encoding the user query, i.e., the user query is transformed into an embedding vector using the same embedding model used in the indexing step.
The semantic search feature in the vector database uses the query embedding to find and return the most relevant chunks.
1️⃣ Query: The user asks a query.
2️⃣ Encode: The embedding model converts the user query into an embedding.
3️⃣ Semantic Search: Most relevant chunks are retrieved by comparing the query embedding against the chunks embeddings saved in the vector database.
4️⃣ Relevant Chunks: The most relevant chunks are returned, which serve as context for the LLM.
𝐀𝐮𝐠𝐦𝐞𝐧𝐭𝐚𝐭𝐢𝐨𝐧
In this step, retrieved relevant chunks are combined to form a context. The context is then combined with the query and instructions to arrive at the LLM prompt.
1️⃣ Combine: Texts from relevant chunks are concatenated into a single string called context.
2️⃣ Augment: The context is combined with the query and instructions to obtain the LLM prompt.
𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐨𝐧
In this step, the prompt having the user query, instructions, and context is given to the LLM. The LLM processes the prompt and then generates a response grounded in the given context.
1️⃣ Feed: The prompt, consisting of a query and context, is given to the LLM.
2️⃣ Generate: The LLM generates the response grounded in the given context.
Thanks for the simple walkthrough for the good 😊