
Top Generative AI Updates of the Week (September Week 4, 2025)
Exa-Code, Perplexity Search API, Qwen3-omni, RexBERT, DeepSeek-V3.1-Terminus,...

Here are the top Generative AI updates of this week
[1] LongCat-Flash-Thinking, SoTA open source reasoning model
[2] DeepSeek introduced DeepSeek-V3.1-Terminus
[3] RexBERT, encoder model for E-commerce texts
[4] Qwen introduced Qwen3-TTS-Flash model
[5] Qwen introduced Qwen3-Omni
[6] Perplexity AI launched Perplexity Email Assistant
[7] Qwen introduced Qwen3-LiveTranslate-Flash
[8] Ollama now has a web search API and MCP server!
[9] Perplexity AI introduced Perplexity Search API
[10] Liquid AI introduces Liquid Nanos Models
[11] Exa Code reduces LLM code hallucination
Let’s see each of these briefly.
[1] LongCat-Flash-Thinking, SoTA open source reasoning model
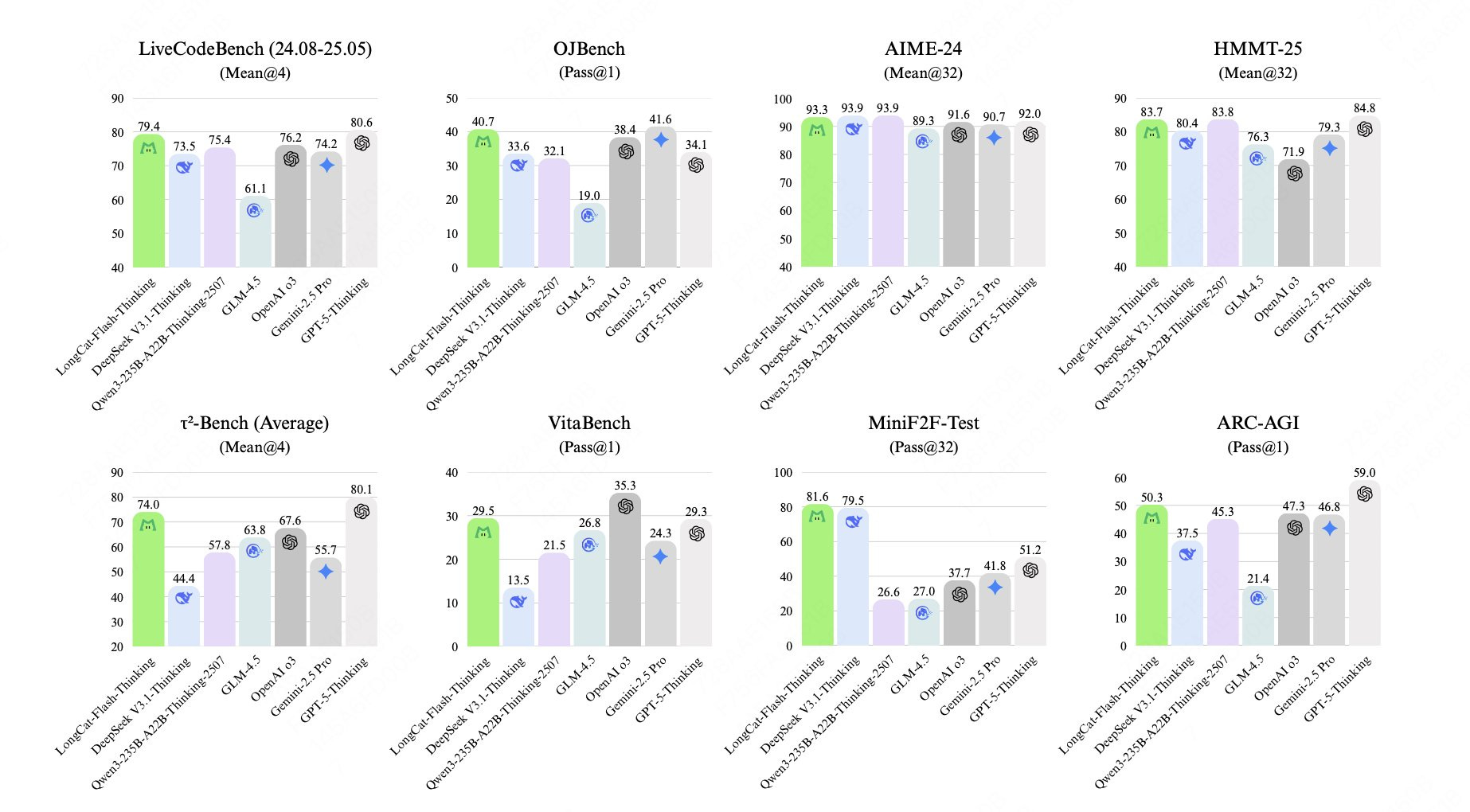
Meituan recently released LongCat-Flash-Thinking (560B parameters), a large reasoning model. This model is designed for state-of-the-art multi-domain reasoning tasks across logic, mathematics, code, and agentic operations. It features an innovative Mixture-of-Experts architecture and leverages a unique domain-parallel reinforcement learning strategy. LongCat-Flash-Thinking delivers remarkable performance and efficiency, setting new records in formal theorem proving and agentic reasoning.
Key Features
560B Mixture-of-Experts, dynamic parameter activation.
Excels at agentic, formal, and informal reasoning tasks.
Uses domain-parallel RL, merges expert capabilities.
DORA system enables rapid, stable scalable asynchronous training.
Sets SOTA results in math, code, and theorem proving.
[2] DeepSeek introduced DeepSeek-V3.1-Terminus
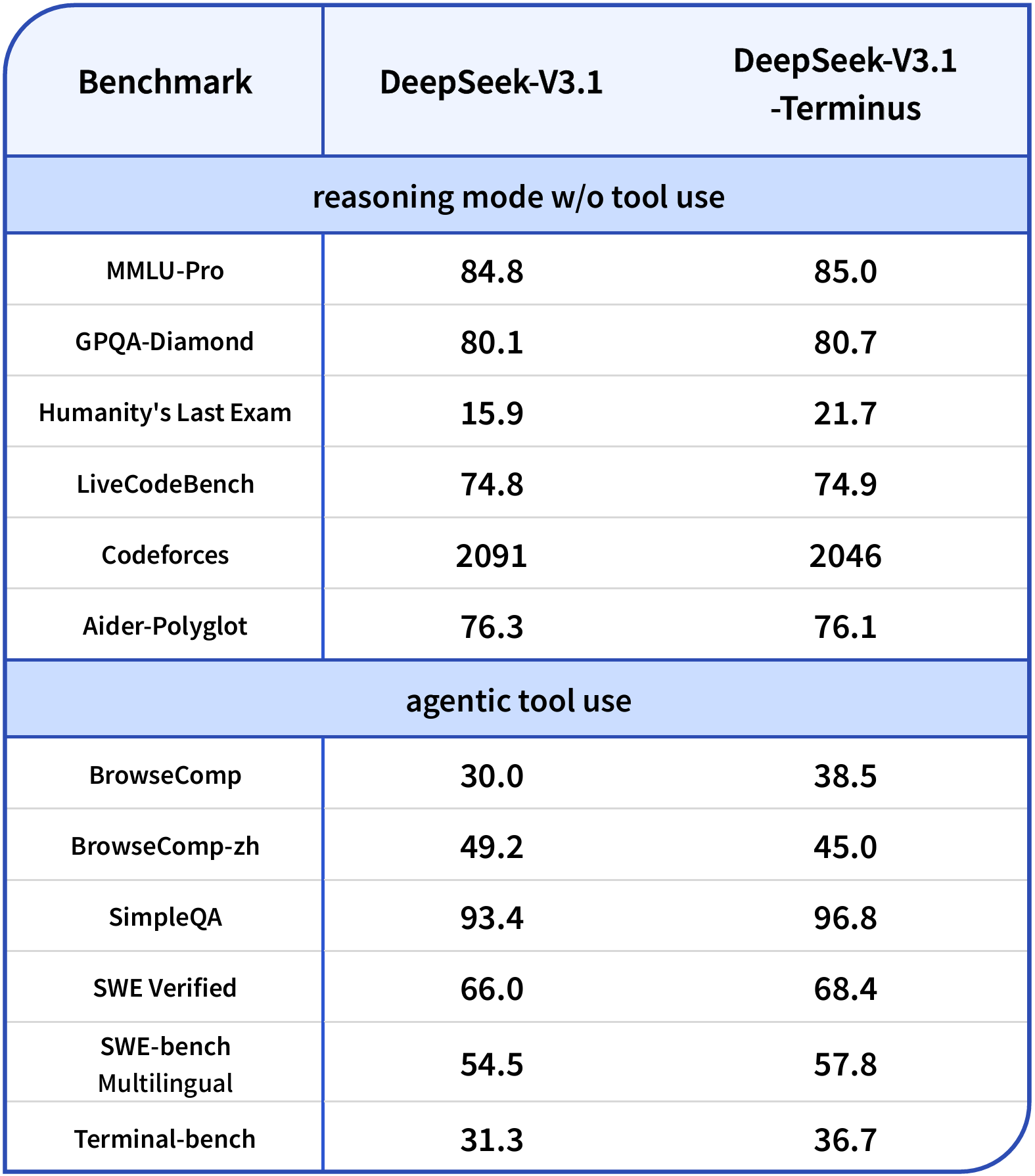
DeepSeek-V3.1-Terminus is a major refinement of DeepSeek’s V3.1 hybrid Mixture-of-Experts model. This release introduces optimized “thinking” and “non-thinking” modes, robust agent/tool use (Code Agent, Search Agent, Terminal Agent), and a greatly expanded 128K-token context window. These enhancements offer fast, reliable outputs and cost efficiency. The model addresses prior language-mixing issues, features enhanced multi-step reasoning, and maintains open-source access with flexible deployment options for developers.
Key Features
Hybrid agentic model with 685B parameter MoE design.
Reasoning and chat modes, up to 128K token context.
Improved Code, Search, and Terminal agent performance.
Consistent linguistic output; fewer mixed-language errors.
Open-source, cost-efficient, and API accessible for all.
[3] RexBERT, an encoder model for E-commerce texts

RexBERT is a family of BERT-style domain-specialized text encoders designed for e-commerce applications. RexBERT is trained on a vast 2.3 trillion token dataset with modern architectural advances. RexBERT excels on e-commerce benchmarks, outperforming larger general models while maintaining efficiency for production scenarios.
Key Features
Specialized for e-commerce, trained on 2.3T+ tokens.
Outperforms larger general models on domain tasks.
Four model sizes: Micro, Mini, Base, and Large.
Released along with new 350B-token Ecom-niverse corpus.
[4] Qwen introduced Qwen3-TTS-Flash model

Qwen3-TTS-Flash is a flagship text-to-speech model released by Alibaba-backed Qwen. This model is designed for ultra-fast, high-quality speech synthesis across multiple languages and dialects. It features state-of-the-art word error rates and speaker similarity, with a particular strength in Mandarin Chinese and English. The model, offers 17 expressive built-in voices and support for nine distinct Chinese dialects. The model achieves exceptionally low first-packet latency (as fast as 97ms), making it particularly suitable for real-time applications such as interactive voice response, gaming, and multimodal assistants.
Key Features
17 expressive voices, each supporting 10 languages.
9 Chinese dialects, including Cantonese, Hokkien, Sichuanese.
State-of-the-art performance in WER and speaker similarity.
Extremely low first-packet latency, down to 97ms.
Optimized for real-time, multilingual, and multi-dialect synthesis.
[5] Qwen introduced Qwen3-Omni

Qwen3-Omni is a state-of-the-art, natively end-to-end multimodal AI model developed by Alibaba. This model processes and generates text, images, audio, and video seamlessly within one unified architecture. It achieves top-tier performance on a wide range of benchmarks while supporting extensive multilingual capabilities and real-time streaming synthesis with very low latency. The model, released under Apache 2.0 license, supports free commercial use and advanced customization for diverse use cases.
Key Features
Native multimodal: text, image, audio, video processing.
State-of-the-art on 22/36 audio and audiovisual benchmarks.
Supports 119 languages text, 19 speech input, 10 speech output.
Very low latency streaming synthesis (~234 ms first-packet latency).
Open-sourced under Apache 2.0 license with free commercial use.
[6] Perplexity AI launched Perplexity Email Assistant
Perplexity AI has recently launched the Perplexity Email Assistant. It is an AI-powered feature designed to act as a personal assistant for email management within Gmail and Outlook. The assistant automates essential inbox tasks like drafting replies, organizing and prioritizing messages, scheduling meetings, and answering specific inbox queries. The email assistant does all these tasks while adapting to the user’s tone and workflow.
Key Features
Exclusive for Perplexity Max subscribers.
Supports Gmail and Outlook integration.
Drafts replies in user’s communication style.
Automates meeting scheduling and inbox organization.
SOC 2 and GDPR compliant; no user data training.
[7] Qwen introduced Qwen3-LiveTranslate-Flash

Qwen3-LiveTranslate-Flash is a newly released AI-driven real-time translation system with minimal latency. It leverages multimodal input—including spoken language, lip movements, gestures, and on-screen text—to achieve high precision and reliability in noisy environments. It provides instant, lossless translations with natural, expressive voice outputs, operating at a near-instant 3-second delay comparable in quality to offline systems.
Key Features
Translates audio/video in real time, 3 seconds latency.
Supports 18 languages and 6 regional dialects.
Vision-enhanced: reads lips, gestures, and on-screen text.
Delivers lossless, high-accuracy translation quality.
Expressive, natural voice synthesis for responses.
[8] Ollama now has a web search API and MCP server!

Ollama has introduced a new web search API and Model Context Protocol (MCP) server. The web search API enables models to directly fetch real-time web data, reducing hallucinations and improving answer accuracy. The MCP server standardizes tool and context integration. Together, these features empower developers to build smarter, context-aware agents and applications that leverage the latest online information.
Key Features
Web search API delivers real-time results for agents.
Generous free tier and cloud-based rate limits.
REST API, Python, JS libraries supported for integration.
MCP server facilitates standardized context exchange.
Reduces hallucinations, supports complex multi-tool workflows.
[9] Perplexity AI introduced Perplexity Search API

The Perplexity Search API gives developers real-time, programmatic access to Perplexity’s massive web index, the same infrastructure behind its public answer engine. Specifically designed for AI applications, it delivers structured, citation-rich results with sub-document precision, rapid updates, and hybrid retrieval. The release includes an SDK and open-source evaluation framework, empowering rapid prototyping and rigorous quality benchmarking while being affordable and privacy-conscious.
Key Features
Access to hundreds of billions of web pages.
Fine-grained retrieval at sub-document level.
Hybrid semantic and keyword search support.
Structured, citation-rich outputs for AI apps.
Real-time indexing and fast, low-latency responses.
[10] Liquid AI introduces Liquid Nanos Models

Liquid AI’s recently launched “Liquid Nanos” are a family of extremely compact, high-performance foundation models (350M–2.6B parameters). These models are trained to deliver frontier-level results on agentic tasks while running directly on everyday devices like smartphones, laptops, and embedded systems. These models offer reliability and efficiency comparable to large-scale LLMs, but with radically lower requirements for cloud infrastructure, cost, energy, and privacy risks. Liquid Nanos enable local AI inference, supporting cutting-edge features in multilingual translation, extraction, reasoning, and agentic tasks across a growing model lineup.
Key Features
Models range from 350M to 2.6B parameters.
Frontier-grade performance on phones, laptops, embedded devices.
Supports RAG, tool calling, and mathematical reasoning.
Enables private, local inference; no cloud dependency.
Zero marginal inference cost, ultra-low energy use.
[11] Exa Code reduces LLM code hallucination

Exa Code is a newly launched web-scale context tool designed specifically for coding agents. It offers rapid, precise code context by indexing over a billion documents, GitHub repositories, and StackOverflow posts. Unlike traditional generic search, Exa Code focuses on extracting highly relevant, token-efficient code examples to significantly minimize hallucinations in LLM-generated code. The tool is open source and, free to use, and streamlines coding workflows by making setup, environment configuration, or SDK usage faster and more reliable.
Key Features
Web-scale context tool for coding agents.
Extracts high-precision code with minimal token use.
Optimized to reduce code hallucinations in LLMs.
Free, open source, with seamless API/platform integration.
Supports a wide range of programming and configuration tasks
References
[1] https://huggingface.co/meituan-longcat/LongCat-Flash-Thinking
[2] https://x.com/deepseek_ai/status/1970117808035074215
[3] https://huggingface.co/blog/thebajajra/rexbert-encoders
[4] https://x.com/Alibaba_Qwen/status/1970163551676592430
[5] https://x.com/Alibaba_Qwen/status/1970181599133344172
[6] https://x.com/AravSrinivas/status/1970165878751973560
[7] https://x.com/Alibaba_Qwen/status/1970565641594867973
[8] https://docs.ollama.com/web-search
[9] https://www.perplexity.ai/hub/blog/introducing-the-perplexity-search-api